DeepSeek V2
传送门:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
本文提出了 DeepSeek V2 模型,旨在降低训练的成本,实现高效推理. 它共有 236B 个参数,激活参数量为 21B,并支持 128K 上下文. 主要采用的创新为 MLA 多头潜在注意力和 DeepSeekMoE.

Structure
由于之前的文章中已经介绍过 DeepSeekMoE 的结果,这里我们主要聚焦 MLA 技术.
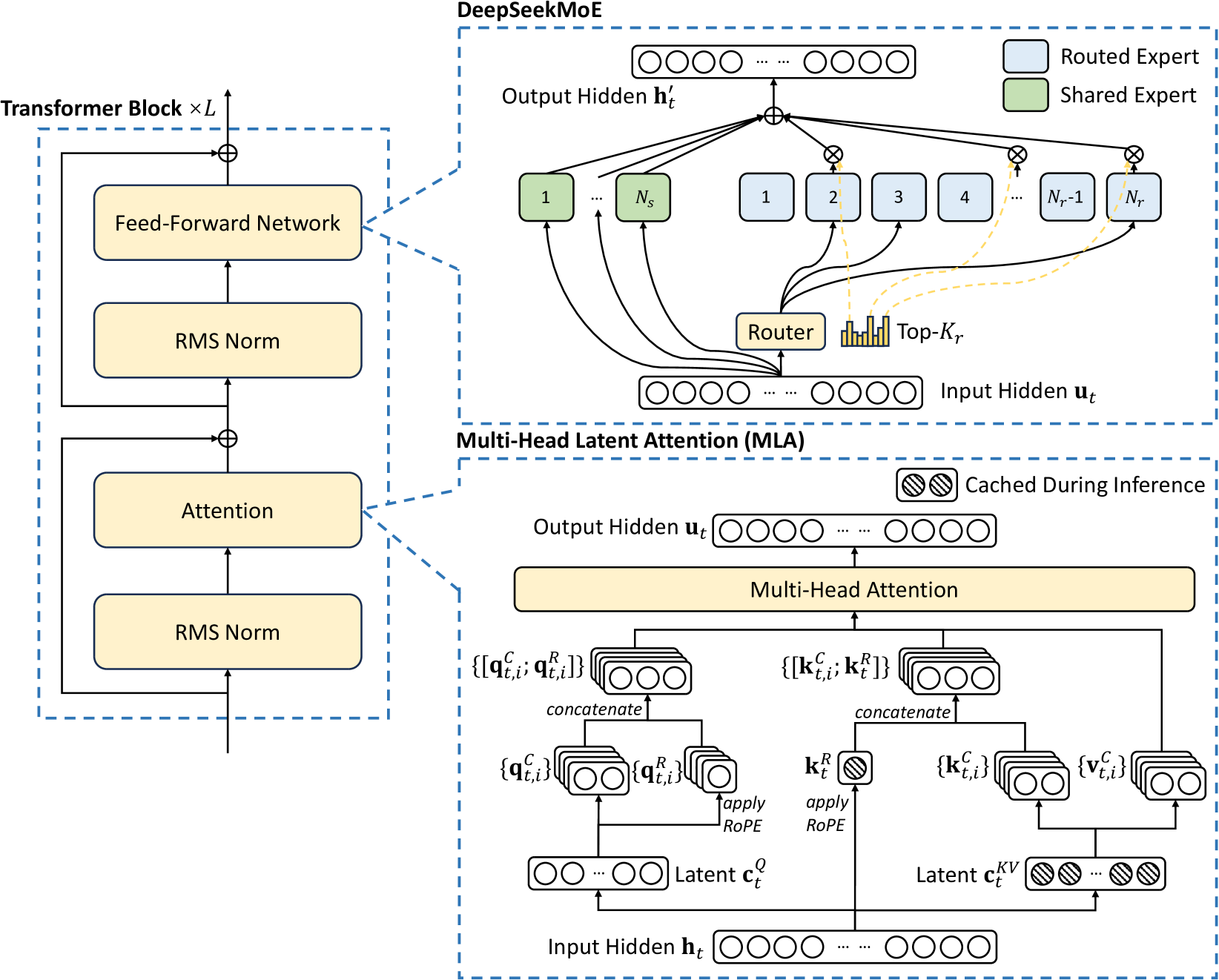
传统 MHA 多头注意力. 令 \(d\) 为嵌入维度,\(n_h\) 为注意力头的数量,\(d_h\) 为每个头的维度,\(\textbf{h}_t\in \mathbb{R}^d\) 为注意力层中第 \(t\) 个 token 的注意力输入. 首先通过三个矩阵 \(W^Q, W^K, W^V\in \mathbb{R}^{d_hn_h\times d}\) 生成 \(\textbf{q}_t, \textbf{k}_t, \textbf{v}_t\in \mathbb{R}^{d_hn_h}\).
\[\begin{aligned} \textbf{q}_t &= W^Q\textbf{h}_t,\\ \textbf{k}_t &= W^K\textbf{h}_t,\\ \textbf{v}_t &= W^V\textbf{h}_t. \end{aligned}\]
然后 \(\textbf{q}_t, \textbf{k}_t, \textbf{v}_t\in \mathbb{R}^{d_hn_h}\) 被切分成 \(n_h\) 个头用于计算多头注意力. \(W^O\in \mathbb{R}^{d\times d_hn_h}\) 是输出投影矩阵.
\[ \begin{aligned}\mathbf{q}_t&=[\mathbf{q}_{t,1};\mathbf{q}_{t,2};...;\mathbf{q}_{t,n_h}],\\\mathbf{k}_t&=[\mathbf{k}_{t,1};\mathbf{k}_{t,2};...;\mathbf{k}_{t,n_h}],\\\mathbf{v}_t&=[\mathbf{v}_{t,1};\mathbf{v}_{t,2};...;\mathbf{v}_{t,n_h}],\\\mathbf{o}_{t,i}&=\sum_{j=1}^{t}\mathrm{Softmax}_{j}(\frac{\mathbf{q}_{t,i}^{T}\mathbf{k}_{j,i}}{\sqrt{d_{h}}})\mathbf{v}_{j,i},\\ \mathbf{u}_t&=W^O[\mathbf{o}_{t,1};\mathbf{o}_{t,2};...;\mathbf{o}_{t,n_h}],\end{aligned} \]
由于所有的 K 和 V 需要被缓存
Experiments
本页面最近更新:,更新历史
发现错误?想一起完善? 在 GitHub 上编辑此页!
本页面贡献者:OI-wiki
本页面的全部内容在 协议之条款下提供,附加条款亦可能应用